
First off, let’s start with a single decision tree before we jump into a forest. Decision trees are predictive models that can be used for both classification problems to evaluate discrete classes such as cat or dog and regression problems to evaluate continuous variables such as age. Decision trees are also known as CART (Classification and Regression Trees). You can look at a decision tree as asking a bunch of questions until you arrive at the answer you are looking for.

Decision Tree Anatomy. One of the great things about decisions trees are that they can be visualized (as an upside-down tree). The anatomy of a decision tree starts with the root node at the top of the tree which gets split into branches that leads to subsets of nodes call internal nodes which are the conditions you use for further splitting. When the tree no longer splits, we reach the leaf nodes which are our decisions.
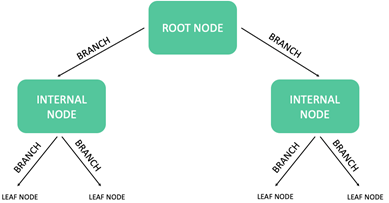
Figure 1: Decision Tree Anatomy
Hmm the decision to reclassify into your PhD or defend your MSc… Say it is the season, where you need to decide whether or not to defend your master’s thesis or reclassify into your PhD. A simple classification decision tree would decide whether to defend or reclassify based on: 1) If you like your project 2) If you like your supervisor 3) If it is beneficial for your career goals
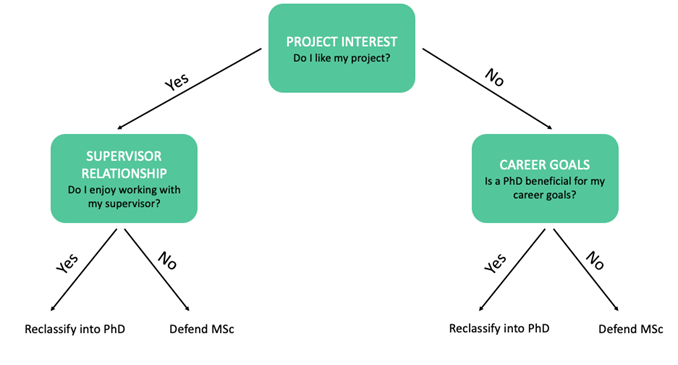
Figure 2: Example Decision Tree for Reclassifying into PhD/Defending MSc
Random Forests Random forests are a supervised machine-learning algorithm that combines multiple decision trees into a single model to make a group decision based on the majority vote for classification problems or the average for regression problems. What makes a random forest…random? Each individual decision tree within a forest takes into account only a subset of features and accesses a random set of training points. This may be hard to visualize with our simple example of only three features, but if you can imagine with 10 features, decision tree one might take features (1,3,4) and decision tree two might take features (2,4,6,7), etc. By selecting a random subset of features for each decision tree we are increasing the diversity of our forest and this helps with overfitting. Overfitting is when your model fits your training data too well but doesn’t perform well on your testing data.
Random Forests and our final decision Now imagine every day from the very beginning of your master’s degree you asked yourself these three questions and a year later you have 365 data points for each day you answered these questions. You may have felt some days you wanted to be done and just defend your master’s and, on some days, you really wanted to continue your project and see it grow. Now you could split this data into a training set to help your model learn more about you, and into a testing set to evaluate based on your experience as a grad student thus far, whether you would like to continue. By taking multiple decision trees (building a forest) the random forest can predict whether you will reclassify or defend based on the results majority vote. So, if your majority of your data points towards reclassifying then that will be the final outcome of your decision tree!
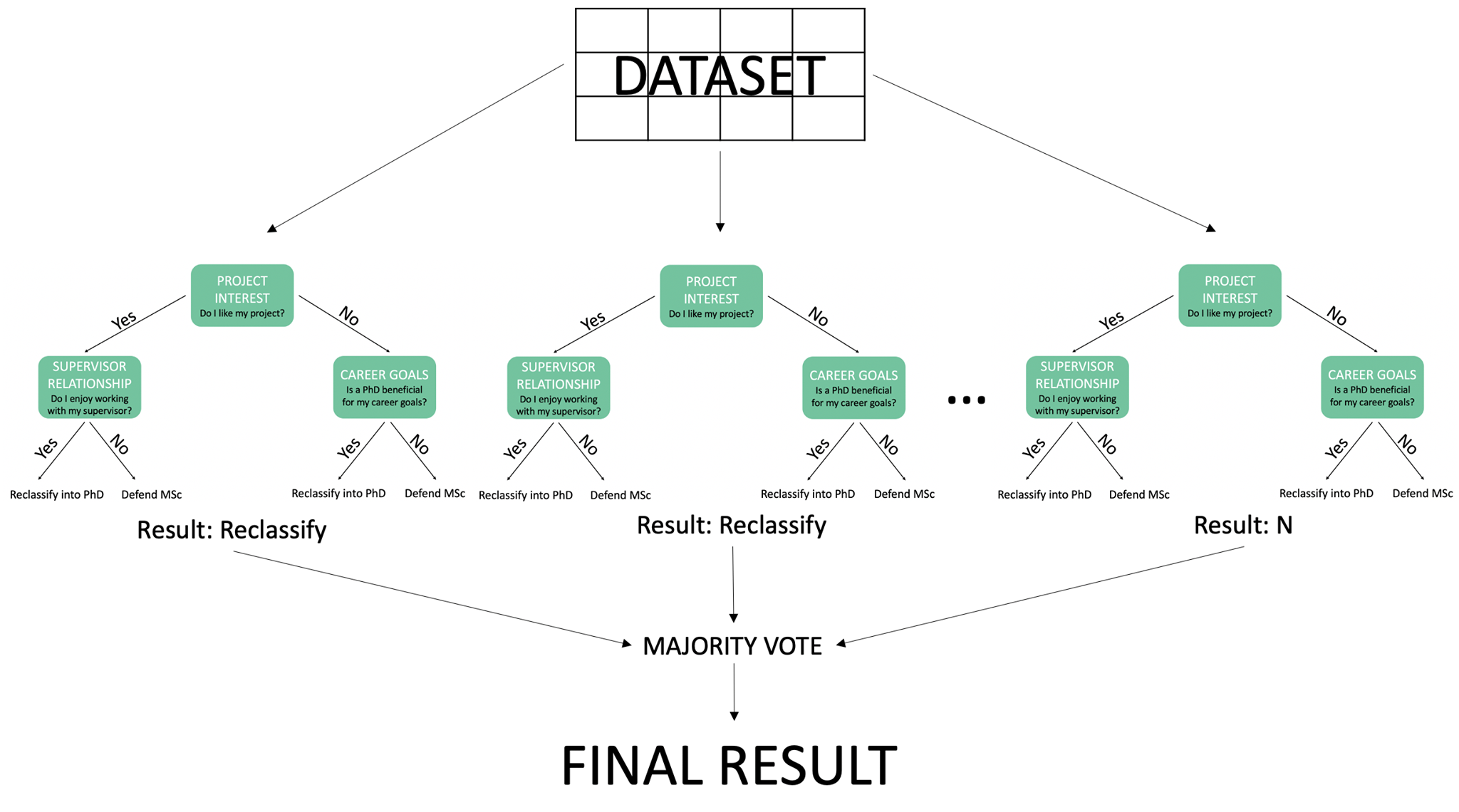
Figure 3: Random Forest Example (N refers to the number of samples)
But in all seriousness do not just use these three attributes to decide whether you want to reclassify into your PhD or not…maybe use four or ten. Hopefully, this was a fun and easy read, stay tuned for part 2 where we take a deeper dive into the equations behind these methods including Gini impurity and entropy!

Author